scan类型命令
1 | SCAN cursor [MATCH pattern] [COUNT count] |
scan:迭代当前库
sscan:迭代一个 set 类型
hscan:迭代一个hash类型,并返回相应的值
zscan:迭代一个sorted set,并且返回相应的分数
redis是单进程单线程模型,keys和smembers这种命令可能会阻塞服务器,所以出现了scan系列的命令,通过返回一个游标,可以增量式迭代.
scan类型命令的实现
scan,sscan,hscan,zsan分别有自己的命令入口,入口中会进行参数检测和游标赋值,然后进入统一的入口函数:scanGenericCommand,以hscan命令为例:
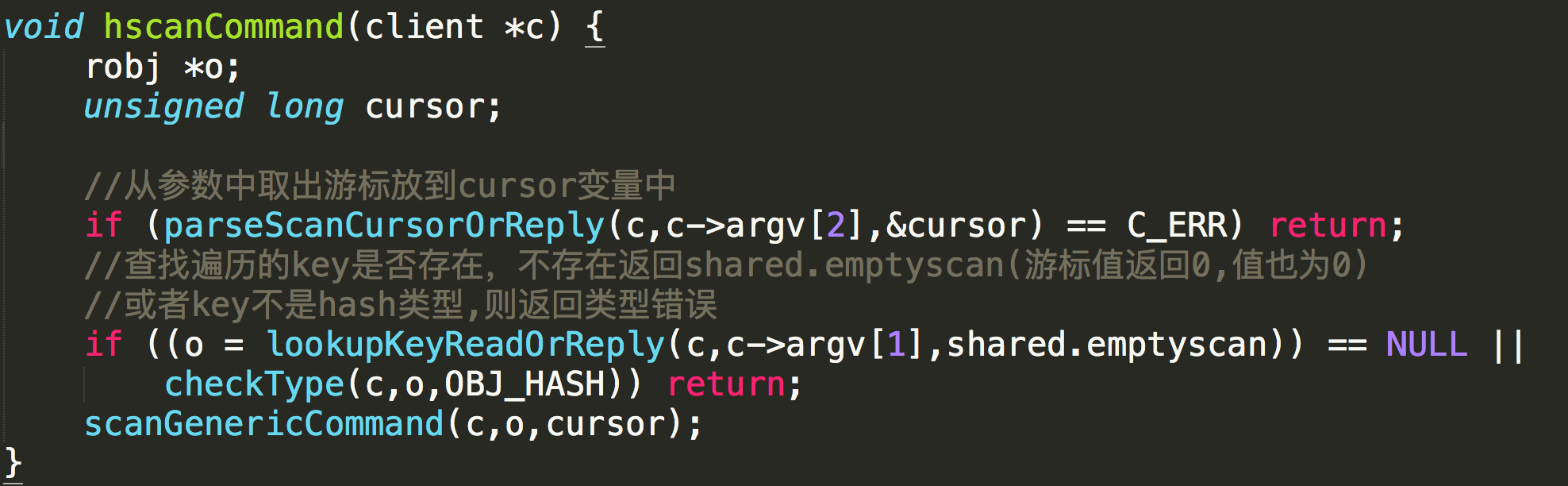
scanGenericCommand主要分四步:
- 解析count和match参数.如果没有指定count,默认返回10条数据
- 开始迭代集合,如果是key保存为ziplist或者intset,则一次性返回所有数据,没有游标(游标值直接返回0).由于redis设计只有数据量比较小的时候才会保存为ziplist或者intset,所以此处不会影响性能.
游标在保存为hash的时候发挥作用,具体入口函数为dictScan,下文详细描述。 - 根据match参数过滤返回值,并且如果这个键已经过期也会直接过滤掉(redis中键过期之后并不会立即删除)
- 返回结果到客户端,是一个数组,第一个值是游标,第二个值是具体的键值对
dictScan中游标的实现
当迭代一个哈希表时,存在三种情况:
- 从迭代开始到结束,哈希表没有进行rehash
- 从迭代开始到结束,哈希表进行了rehash,但是每次迭代时,哈希表要么没开始rehash,要么已经结束了rehash
- 从迭代开始到结束,某次或某几次迭代时哈希表正在进行rehash
redis中进行rehash时会存在两个哈希表,ht[0]与ht[1],并且是渐进式rehash(即不会一次性全部rehash);新的键值对会存放到ht[1]中并且会逐步将ht[0]的数据转移到ht[1].全部rehash完毕后,ht[1]赋值给ht[0]然后清空ht[1].
因此游标的实现需要兼顾以上三种情况,以上三种情况的游标实现要求如下:
- 第一种情况比较简单,假设redis的哈希表大小为4,则第一次游标为0,读取第一个bucket的数据,然后游标返回1,下次读取第二个bucket的位置,依次遍历
- 第二种情况比较复杂,假设redis的哈希表大小为4,如果rehash完后size变成了8.如果仍然按照上边的思路返回游标,则如下图:

假设bucket0读完之后返回了游标1,当客户端再次带着游标1返回时哈希表已经进行完rehash,并且size扩大了一倍变成了8.redis按如下方法计算一个键的bucket:
1 | hash(key)&(size-1) |
即如果size是4时,hash(key)&11,如果size是8时,hash(key)&111.因此当从4扩容到8时,原先在0bucket的数据会分散到0(000)与4(100)两个bucket,bucket对应关系表如下:
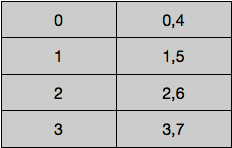
从二进制来看,当size为4时,hash(key)之后取低两位即 hash(key)&11即key的bucket位置,如果size为8时,bucket位置为 hash(key)&111,即取低三位,当低两位为00时,如果第三位为0,则为000,如果第三位为1,则为100,正好是4.其他槽位的类似.所以如果此时继续按第一种方法遍历,第四个bucket取到的值全部为重复值
- 第三种情况,如果返回游标1时正在进行rehash,ht[0]中的bucket 1中的部分数据可能已经rehash到 ht[1]中的bucket[1]或者bucket[5],此时必须将ht[0]和ht[1]中的相应bucket全部遍历,否则可能会有遗漏数据
所以为了兼顾以上三种情况,做到不漏数据并且尽量不重复,redis使用了一种叫做reverse binary iteration的方法.具体的游标计算代码如下:
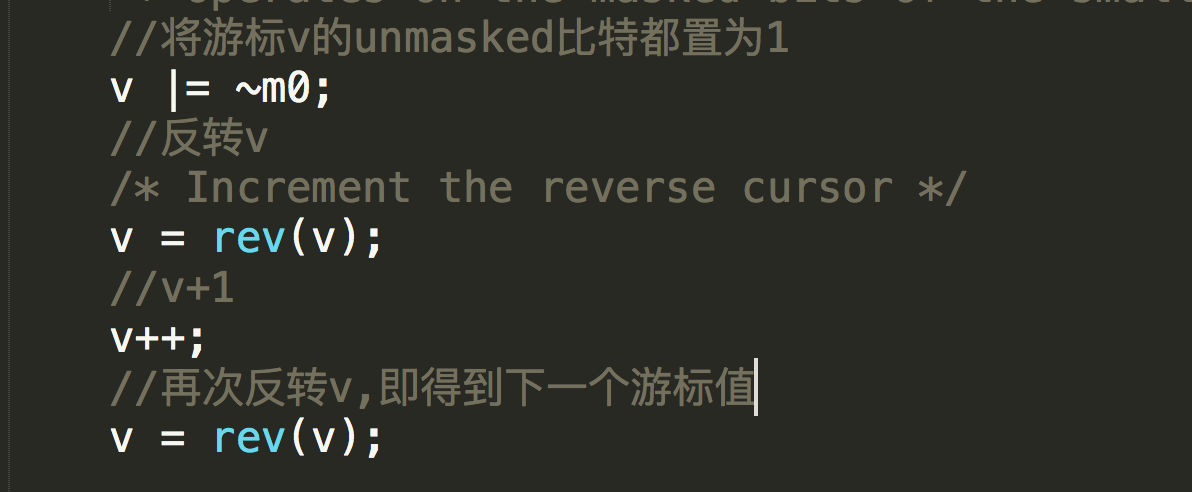
代码逻辑很简单,下面示例从4变为8和从4变为16以及从8变为4和从16变为4时,这种方法为何能够做到不重不漏

遍历size为4时的游标状态转移为0-2-1-3.
同理,size为8时的游标状态转移为0-4-2-6-1-5-3-7.
size为16时的游标状态转义为0-8-4-12-2-10-6-14-1-9-5-13-3-11-7-15
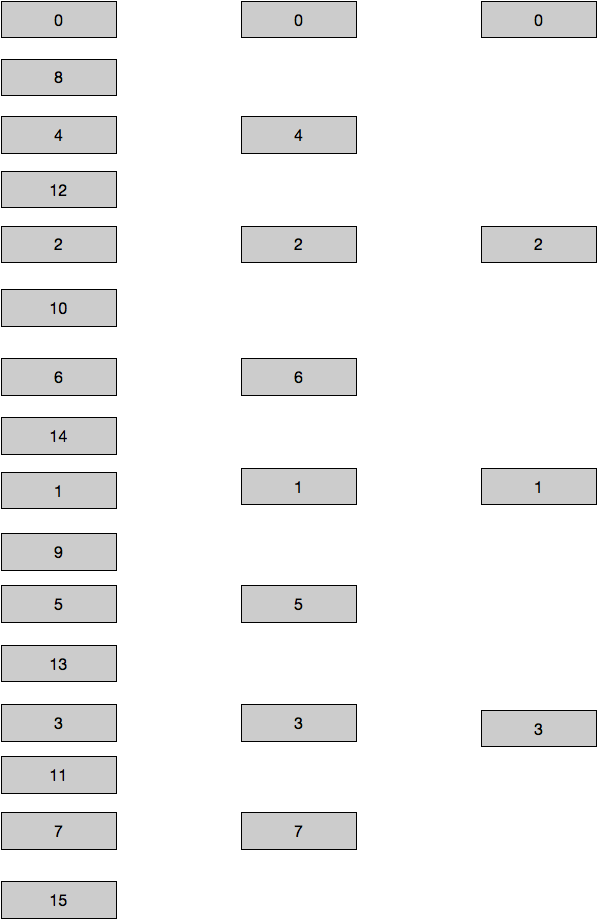
可以看出,当size由小变大时,所有原来的游标都能在大的hashTable中找到相应的位置,并且顺序一致,不会重复读取并且不会遗漏
例如size原来是4变为了8,且第二次遍历时rehash已经完成.此时游标为2,根据图2,我们知道size为4时的bucket2会rehash到size为8时的2和6.而size为4时的bucket0rehash到size为8时的0和4
由于bucket 0 已经遍历完,也即size为8时的0,4已经遍历,正好开始从2开始继续遍历,不重复也不会遗漏
继续考虑size由大变小的情况.假设size由16变为了4,分两种情况,一种是游标为0,2,1,3中的一种,此时继续读取,也不会遗漏和重复
但如果游标返回的不是这四种,例如返回了10,10&11之后变为了2,所以会从2开始继续遍历.但由于size为16时的bucket2已经读取过,并且2,10,6,14都会rehash到size为4的bucket2,所以会造成重复读取
size为16时的bucket2。即有重复但不会遗漏
总结一下:redis里边rehash从小到大时,scan系列命令不会重复也不会遗漏.而从大到小时,有可能会造成重复但不会遗漏.
截止目前,情况1和情况2已经比较完美的处理了。情况3看看如何处理
情况3需要从ht[0]和ht[1]中都取出数据,主要的难点在于如何在size大的哈希表中找到应该取哪些bucket.redis代码如下:
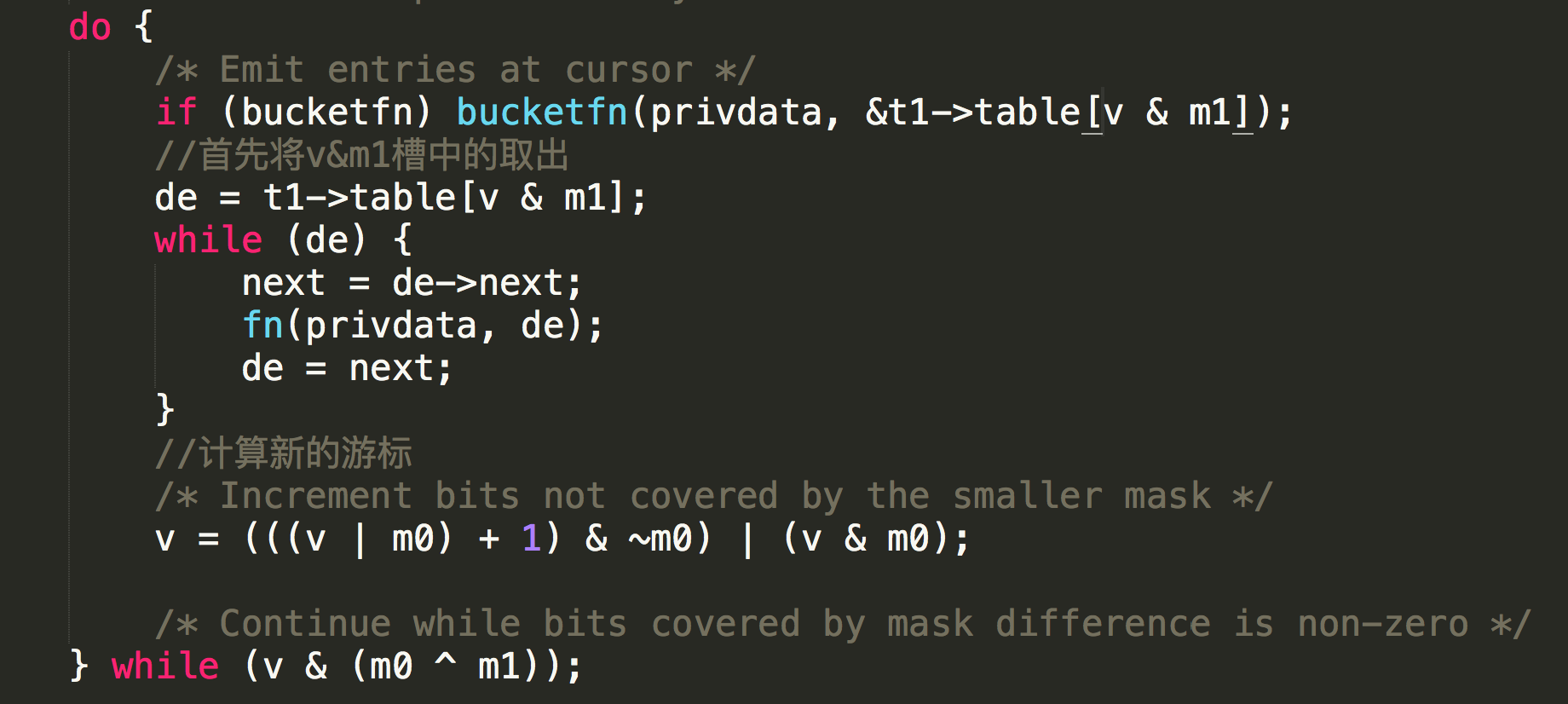
判断条件为:
1 | v&(m0^m1) |
size 4的m0为00000011,size8的m1为00000111,二者异或之后取值为00000100,即取二者mask高位的值,然后&v,看游标是否在高位还有值
下一个游标的取值方法为
1 | v = ( ((v | m0) +1)& ~m0) | ( v & m0) |
右半部分 取v的低位,左半部分取v的高位。 (v&m0)取出v的低位 例如size = 4时为 v&00000011
左半部分 (v|m0) + 1即将v的低位都置为1,然后+1之后会进位到v的高位,再次 & ~m0之后即取出了v的高位
整体来看每次将游标v的高位加1.下边举例来看:
假设游标返回了2,并且正在进行rehash,此时size由4变成了8 .则m0 = 00000011 v = 00000010
根据公式计算出的下一个游标为 ( (( 00000010|00000011) +1 ) & (11111100) )| (00000010 & 00000011) = (00000100)&(11111100)|(00000010) = (00000110) 正好是6
判断条件为 (00000010) & (00000011 ^ 00000111) = (00000010) & (00000100) = (00000000) 为0,结束循环