lru是什么
lru(least recently used)是一种缓存置换算法。即在缓存有限的情况下,如果有新的数据需要加载进缓存,则需要将最不可能被继续访问的缓存剔除掉。因为缓存是否可能被访问到没法做预测,所以基于如下假设实现该算法:
如果一个key经常被访问,那么该key的idle time应该是最小的。
(但这个假设也是基于概率,并不是充要条件,很明显,idle time最小的,甚至都不一定会被再次访问到)
这也就是lru的实现思路。首先实现一个双向链表,每次有一个key被访问之后,就把被访问的key放到链表的头部。当缓存不够时,直接从尾部逐个摘除。
在这种假设下的实现方法很明显会有一个问题,例如mysql中执行如下一条语句:
1 | select * from table_a; |
如果table_a中有大量数据并且读取之后不会继续使用,则lru头部会被大量的table_a中的数据占据。这样会造成热点数据被逐出缓存从而导致大量的磁盘io
mysql innodb的buffer pool使用了一种改进的lru算法,大意是将lru链表分成两部分,一部分为newlist,一部分为oldlist,newlist是头部热点数据,oldlist是非热点数据,oldlist默认占整个list长度的3/8.当初次加载一个page的时候,会首先放入oldlist的头部,再次访问时才会移动到newlist.具体参考如下文章:
https://dev.mysql.com/doc/refman/8.0/en/innodb-buffer-pool.html
而Redis整体上是一个大的dict,如果实现一个双向链表需要在每个key上首先增加两个指针,需要16个字节,并且额外需要一个list结构体去存储该双向链表的头尾节点信息。Redis作者认为这样实现不仅内存占用太大,而且可能导致性能降低。他认为既然lru本来就是基于假设做出的算法,为什么不能模拟实现一个lru呢。
Redis中的实现
首先Redis并没有使用双向链表实现一个lru算法。具体实现方法接下来逐步介绍
首先看一下robj结构体(Redis整体上是一个大的dict,key是一个string,而value都会保存为一个robj)
1 |
|
我们看到每个robj中都有一个24bit长度的lru字段,lru字段里边保存的是一个时间戳。看下边的代码
1 | robj *lookupKey(redisDb *db, robj *key, int flags) { |
在Redis的dict中每次按key获取一个值的时候,都会调用lookupKey函数,如果配置使用了lru模式,该函数会更新value中的lru字段为当前秒级别的时间戳(lfu方式后文再描述)。
那么,虽然记录了每个value的时间戳,但是淘汰时总不能挨个遍历dict中的所有槽,逐个比较lru大小吧。
Redis初始的实现算法很简单,随机从dict中取出五个key,淘汰一个lru字段值最小的。(随机选取的key是个可配置的参数maxmemory-samples,默认值为5).
在3.0的时候,又改进了一版算法,首先第一次随机选取的key都会放入一个pool中(pool的大小为16),pool中的key是按lru大小顺序排列的。接下来每次随机选取的keylru值必须小于pool中最小的lru才会继续放入,直到将pool放满。放满之后,每次如果有新的key需要放入,需要将pool中lru最大的一个key取出。
淘汰的时候,直接从pool中选取一个lru最小的值然后将其淘汰。
我们知道Redis执行命令时首先会调用processCommand函数,在processCommand中会进行key的淘汰,代码如下:
1 |
|
可以看到,lru本身是基于概率的猜测,这个算法也是基于概率的猜测,也就是作者说的模拟lru.那么效果如何呢?作者做了个实验,如下图所示

首先加入n个key并顺序访问这n个key,之后加入n/2个key(假设redis中只能保存n个key,于是会有n/2个key被逐出).上图中浅灰色为被逐出的key,淡蓝色是新增加的key,灰色的为最近被访问的key(即不会被lru逐出的key)
左上图为理想中的lru算法,新增加的key和最近被访问的key都不应该被逐出。
可以看到,Redis2.8当每次随机采样5个key时,新增加的key和最近访问的key都有一定概率被逐出
Redis3.0增加了pool后效果好一些(右下角的图)。当Redis3.0增加了pool并且将采样key增加到10个后,基本等同于理想中的lru(虽然还是有一点差距)
如果继续增加采样的key或者pool的大小,作者发现很能进一步优化lru算法,于是作者开始转换思路。
上文介绍了实现lru的一种思路,即如果一个key经常被访问,那么该key的idle time应该是最小的
那么能不能换一种思路呢。如果能够记录一个key被访问的次数,那么经常被访问的key最有可能再次被访问到。这也就是lfu(least frequently used),访问次数最少的最应该被逐出
lfu的代码如下:
1 | void updateLFU(robj *val) { |
lfu本质上是一个概率计数器,称为morris counter.随着访问次数的增加,counter的增加会越来越缓慢。如下是访问次数与counter值之间的关系
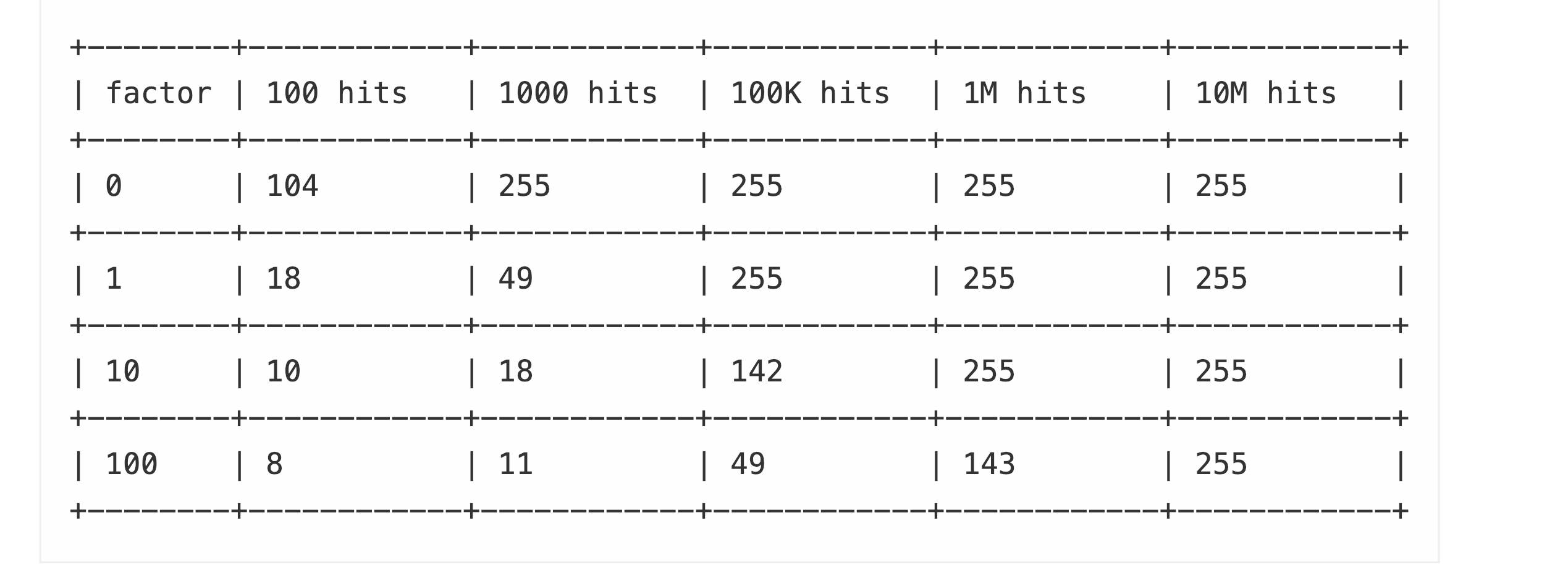
factor即server.lfu_log_facotr配置值,默认为10.可以看到,一个key访问一千万次以后counter值才会到达255.factor值越小, counter越灵敏
lfu随着分钟数对counter做衰减是基于一个原理:过去被大量访问的key不一定现在仍然会被访问。相当于除了计数,给时间也增加了一定的权重。
淘汰时就很简单了,仍然是一个pool,随机选取10个key,counter最小的被淘汰
算法验证
redis-cli提供了一个参数,可以验证lru算法的效率。主要是通过验证hits/miss的比率,来判断淘汰算法是否有效。命中比率高说明确实淘汰了不会被经常访问的key.具体做法如下:
配置redis lru算法为 allkeys-lru
1 | test ~/redis-5.0.0$./src/redis-cli -p 6380 |
执行redis-cli –lru-test验证命中率
1 | ./src/redis-cli -p 6380 --lru-test 1000000//模拟100万个key |
通过info查看使用的内存和被逐出的keys
1 | ... |
查看lru-test的输出
1 | 131250 Gets/sec | Hits: 124113 (94.56%) | Misses: 7137 (5.44%) |
大概有5%-5.5%之间的miss概率。我们将lru策略切换为allkeys-lfu,再次实验
结果如下:
1 | 131250 Gets/sec | Hits: 124480 (94.84%) | Misses: 6770 (5.16%) |
%5左右的miss率,在这个测试下,lfu比lru的预测准确率略微高一些。
在实际生产环境中,不同的redis访问模式需要配置不同的lru策略, 然后可以通过lru test工具验证效果。