proxy启动
cmd/proxy/main.go文件
解析配置文件之后重点是proxy.New(config)函数
该函数中,首先会创建一个Proxy结构体,如下:
1 | type Proxy struct { |
然后起两个协程,分别处理11080和19000端口的请求
1 | go s.serveAdmin() |
我们重点看s.serveProxy()的处理流程,即redis client连接19000端口后proxy如何分发到codis server并且将结果返回到客户端
Proxy处理
s.serverProxy也启动了两个协程,一个协程对router中连接池中的连接进行连接可用性检测,另一个协程是一个死循环,accept lproxy端口的连接,并且启动一个新的Session进行处理,代码流程如下:
1 | go func(l net.Listener) (err error) { |
首先介绍一下Request结构体,该结构体会贯穿整个流程
1 | type Request struct { |
Start函数处理流程如下:
1 | tasks := NewRequestChanBuffer(1024)//tasks是一个指向RequestChan的指针,RequestChan结构体中有一个data字段,data字段是个数组,保存1024个指向Request的指针 |
可以看到,s.loopWriter只是从RequestChan的data字段中取出请求并且返回给客户端,通过上文Request结构体的介绍,可以看到,通过在request的Batch执行wait操作,只有请求处理完成后loopWriter才会执行
下边我们看loopReader的执行流程
1 | r := &Request{} //新建一个Request结构体,该结构体会贯穿请求的始终,请求字段,响应字段都放在Request中 |
看handleRequest函数如何处理请求,重点是router的dispatch函数
1 | func (s *Router) dispatch(r *Request) error { |
forward函数调用process函数,返回一个BackendConn结构,然后调用其PushBack函数将请求放入bc.input中
1 | func (d *forwardSync) Forward(s *Slot, r *Request, hkey []byte) error { |
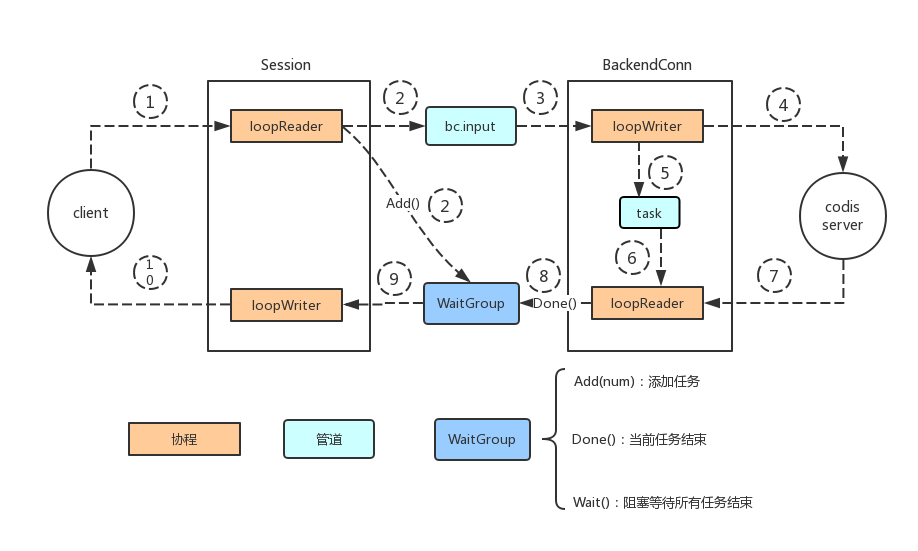
至此可以看到,Proxy的处理流程
1 | loopWriter->RuquestChan的data字段中读取请求并且返回。在Batch处等待 |
很明显,Proxy并没有真正处理请求,肯定会有goroutine从bc.input中读取请求并且处理完成后在Batch处减1,这样当请求执行完成后,loopWriter就可以返回给客户端端响应了。
BackendConn的处理流程
从上文得知,proxy结构体中有一个router字段,类型为Router,结构体类型如下:
1 | type Router struct { |
Router的pool中管理连接池,执行fillSlot时会真正生成连接,放入Slot结构体的backend字段的bc字段中,Slot结构体如下:
1 | type Slot struct { |
我们看一下bc字段的结构体sharedBackendConn:
1 | type sharedBackendConn struct { |
每个BackendConn中有一个 input chan *Request字段,是一个channel,channel中的内容为Request指针。也就是第二章节loopReader选取一个BackendConn后,会将请求放入input中。
下边我们看看处理BackendConn input字段中数据的协程是如何启动并处理数据的。代码路径为pkg/proxy/backend.go的newBackendConn函数
1 |
|
可以看到,在此处创建的BackendConn结构,并且初始化bc.input字段。连接池的建立是在proxy初始化启动的时候就会建立好。继续看bc.run()函数的处理流程
1 | func (bc *BackendConn) run() { |
注意此处的loopWriter会从bc.input中取出数据发送到codis server,bc.newBackendReader会起一个loopReader,从codis server中读取数据并且写到request结构体中,此处的loopReader和loopWriter通过tasks这个channel通信。
1 | func (bc *BackendConn) newBackendReader(round int, config *Config) (*redis.Conn, chan<- *Request, error) { |
总结一下,BackendConn中的函数功能如下
1 | loopWriter->从bc.input中取出请求并且发给codis server,并且将请求放到tasks channel中 |
小结
一图胜千言,图片版权归李老师,如下