ziplist简介
Redis使用ziplist是为了节省内存.以zset为例,当zset元素个数少并且每个元素也比较小的时候,如果直接使用skiplist(可以理解为多层的双向链表),每个节点的前后指针这些元数据占用空间的比例可能达到50%以上.而ziplist是分配在堆上的一块连续内存,通过一定的编码格式,使数据保存更加紧凑.如下是一个编码为ziplist的zset.
1 | 127.0.0.1:6666> zadd zs 100 'a' |
ziplist格式
ziplist的格式如下图所示: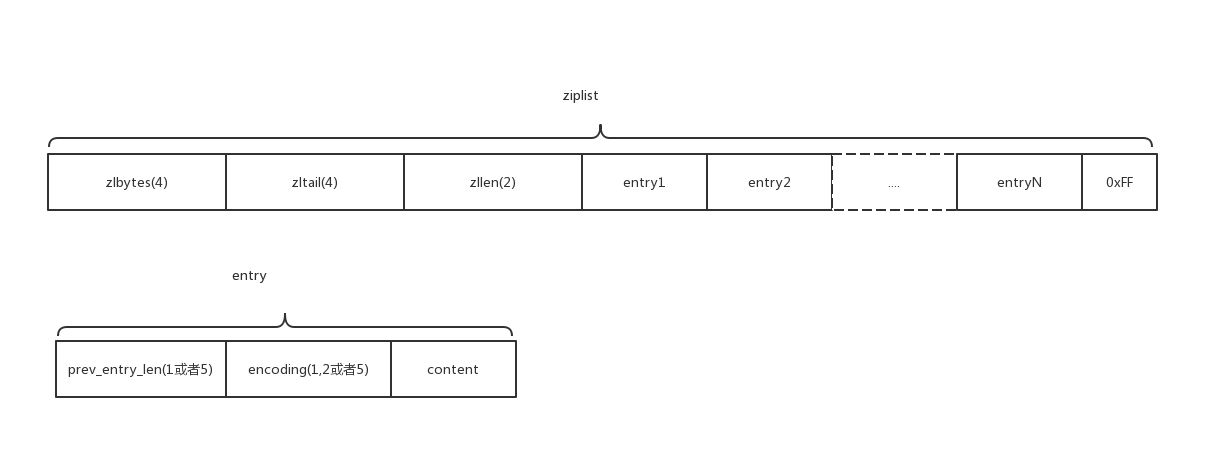
ziplist各字段解释如下:
- zlbytes:ziplist占用的内存空间大小
- zltail:ziplist最后一个entry的偏移量
- zllen:ziplist中entry的个数.
- entry:每个元素
- 0xFF:ziplist的结束标志
每个entry的字段解释如下:
- prev_entry_len:前一个entry占用的字节大小,占用1个或者5个字节.当小于254时,占用1字节,当大于等于254时,占用5字节
- encoding:当前entry内容的编码格式及其长度
- content:当前entry保存的内容
注意ziplist中有一个zltail字段是最后一个entry的偏移量,通过该字段定位到最后一个entry后,读取prev_entry_len可以继续向前定位上一个entry的起始地址.也就是说ziplist适合于从后往前遍历.
bug原因及其复现
首先看下代码中是如何修复该bug的,然后通过把代码反向修改回来,可以构造示例复现该bug.通过复现过程详细描述该bug的产生过程
1 | @@ -778,7 +778,12 @@ unsigned char *__ziplistInsert(unsigned char *zl, unsigned char *p, unsigned cha |
可以看到代码中增加了一个判断
1 | if (nextdiff == -4 && reqlen < 4) |
我们看看nextdiff是如何计算的
1 | int zipPrevLenByteDiff(unsigned char *p, unsigned int len) { |
如上函数计算nextdiff,可以看出,根据插入位置p当前保存prev_entry_len字段的字节数和即将插入的entry需要的字节数相减得出nextdiff.值有三种类型
- 0: 空间相等
- 4:需要更多空间
- -4:空间富余
bug修复过程首先判断nextdiff等于-4,即p位置的prev_entry_len为5个字节,而当前要插入的entry的长度只需要1个字节去保存.然后判断reqlen < 4.看到此处可能读者会有疑惑,既然prev_entry_len长度已经为5个字节了,那么新插入的值prev_entry_len+encoding+content字段肯定会大于5字节,为什么会出现小于4的情况呢?
这种情况确实比较费解,通过下文的构造示例我们能够看出,在连锁更新的时候,为了防止大量的重新分配空间的动作,如果一个entry的长度只需要1个字节就能够保存,但是连锁更新时如果原先已经为prev_entry_len分配了5个字节,则不会进行缩容操作.
把bug修复代码反向修改回来,编译之后执行如下命令可以导致Redis crash(注意前边是命令编号,下文通过该编号解释Redis中ziplist内存的变化情况):
1 | 0.redis-cli del list |
前6条命令会往一个list中分别插入’one’,’two’,252个’A’,250个’A’,’three’,’a’六个元素.此时内存占用情况如下:
每个小矩形框表示占用内存字节数,大矩形框表示一个个entry,每个entry有三项,分别为prev_entry_len,encoding和content字段
接着执行第7条命令,内存占用情况如图,表示如下: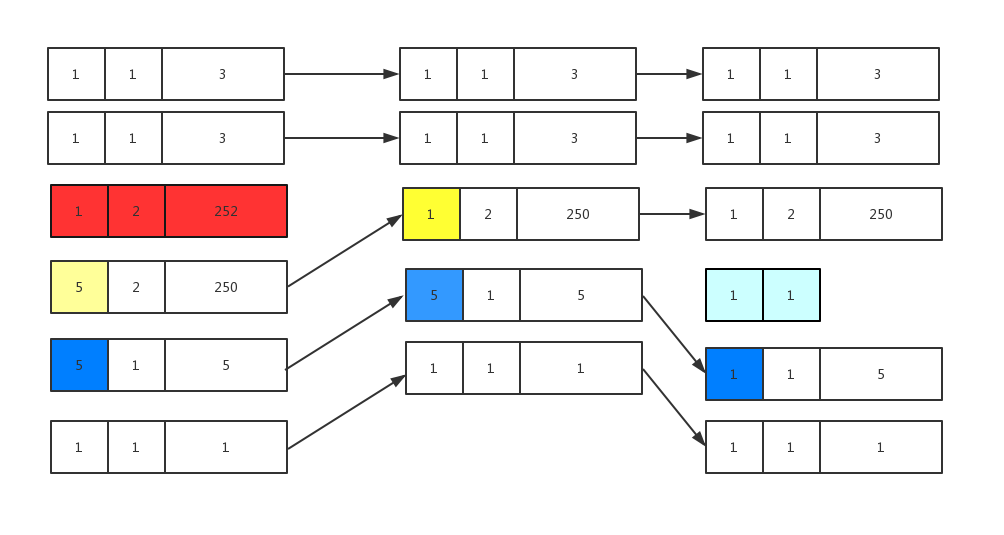
删除了第3个entry,此时第4个entry的前一个entry长度由255字节变为5字节(第2个entry此时为第4个entry的前一个entry),所以prev_entry_len字段由占用5个字节变为占用1个字节.参见图中黄框部分.
注意此时会发生连锁更新,因为蓝框部分的prev_entry_len由257字节变为253,也可以更新为1个字节.但Redis中在连锁更新的情况下为了避免频繁的realloc操作,这种情况下不进行缩容.
接着执行第8条命令,插入绿框中的数据(见图第3列所示),此时蓝筐中的prev_entry_len是5个字节,绿框中的数据只占用2字节,当将prev_entry_len更新为1字节后,prev_entry_len多余的4字节可以完整的容纳绿框中的数据.
即虽然插入了数据,但realloc之后反而缩小了占用的内存,从而导致ziplist中的数据损坏.
修复这个bug的代码也就很容易理解了,即图中第3列蓝框的prev_entry_len仍然保留为5个字节.
可以进一步构造另一种情况,即第6步构造为rpush list 10,则此时不会造成redis crash,而是会丢失10这个元素.读者可以画出内存占用图自行分析
redis作者对该bug的思考
通过上边的分析,是不是觉着很难理解?Redis作者也意识到由于连锁更新的存在导致ziplist并不是简单易懂.于是提出了一个优化后的替代结构listpack.
listpack主要做了如下两点改进:
- 头部省去了4个字节的zltail字段
- entry中不再保存prev_entry_len这个字段,而是改为保存本entry自己的长度
整体结构如下:
1 | <tot-bytes> <num-elements> <element-1> ... <element-N> <listpack-end-byte> |
每个entry的结构如下:
1 | <encoding-type><element-data><element-tot-len> |
我们知道ziplist设计为适合从尾部到头部逐个遍历,那么listpack如何实现该功能呢?
首先通过tot-bytes偏移到结尾,然后从右到左读取element-tot-len(注意该字段设计为从右往左读取),这样既实现了尾部到头部的遍历,又没有连锁更新的情况.是不是很巧妙.
参考文档
- https://gist.github.com/antirez/66ffab20190ece8a7485bd9accfbc175
- https://raw.githubusercontent.com/antirez/redis/4.0/00-RELEASENOTES
- https://github.com/antirez/redis/commit/8327b813#diff-b109b27001207a835769c556a54ff1b3
- https://github.com/antirez/redis/commit/8327b813#diff-b109b27001207a835769c556a54ff1b3