解决什么问题
先看一个示例,假设hash table初始的slots为4,hash函数为uid%4,并且uid分布均匀,我们看下uid分别为0-11时的分布
| slots | 0 | 1 | 2 | 3 |
|---|---|---|---|---|
| 0 | 1 | 2 | 3 | |
| 4 | 5 | 6 | 7 | |
| 8 | 9 | 10 | 11 |
假设现在扩容,slots变为5,我们看下分布
| slots | 0 | 1 | 2 | 3 | 4 |
|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | |
| 5 | 6 | 7 | 8 | 9 | |
| 10 | 11 | ||||
| 需要调整4-11共8个key |
那直接按2倍扩容呢,slots变为8
slots|0|1|2|3|4|5|6|7
——-|——-|—-|—-|—-|—-|—-|—-|—-|—-
|0 | 1 |2| 3| 4|5|6|7
|8 | 9 |10|11||||
可以看到需要调整4-7共4个key,基本上按2倍扩容,需要调整一半的key
将以上情形扩展一下,想象一个分布式缓存的情形,slots的个数就是分布式缓存node的个数,那么分布式缓存会根据容量时常动态调整node的个数.此时用传统的hash后取模的方法,需要调整大量的key.同样在CDN的场景下,动态增缩CDN的节点个数也存在同样的问题.
一致性哈希就是解决这个问题,当动态缩扩容时,平均来说只会有k/N个key被重新remap,k为所有key的个数,N为slots或者说node的个数.
如何实现
hash表的rehash问题经常会遇到,我们知道redis中通过两个hash表h0和h1解决rehash的问题.当需要扩容或者缩容时,存量和增量key分别按如下方式处理:
- 存量:渐进式逐步将h0中的key重新map到h1
- 增量:直接挂载到h1,因此读取时会判断如果正在进行rehash,则读取完h0之后还需要继续读取h1
由于是渐进式逐步remap,并且hash table的读取是O(1)复杂度,因此rehash对redis性能几乎无影响.那么这种方法能不能用到第一节中提到的问题呢?答案是不行
Redis的rehash是一个单机版本,进程内部的rehash,存量增量都可以由redis自己处理,对应用无感知.而第一节提到的问题是多台机器,应用依赖于hash的结果去相应的机器获取数据.一般来说,增减node必须等待数据重新remap完成后才能正式生效.
继续考虑一致性hash的实现,先考虑一种极端情况,即假设key是单调递增的
则hash分布可以考虑如下方案:
1-10000分布到node1,10001-20000分布到node2….
扩容时只需要增加机器节点,存量数据并不受影响.缩容时也只需要remap待缩容的机器
这种情况比较极端,我们看下一般情况下如何实现一致性hash
一致性hash原理示意图:
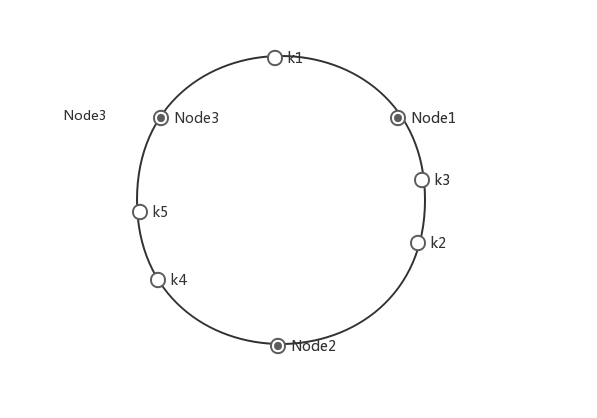
图中有三个节点Node1,Node2,Node3以及五个key k1,k2,k3,k4,k5,首先将节点hash为一个最大0-2^32-1的值,然后将五个key也用同样的hash函数hash为0-2^32-1的值.假设node哈希之后的值为500,1600000,8000000,并且k1哈希之后的值为400,则取第一个大于400的node即Node1;假设k2哈希之后的值为150000,则大于150000的第一个node为Node2,以此类推
为什么这样hash之后如果扩缩容会减少需要remap的节点呢,大家简单画一下即可理解,例如增加一个node4,如图: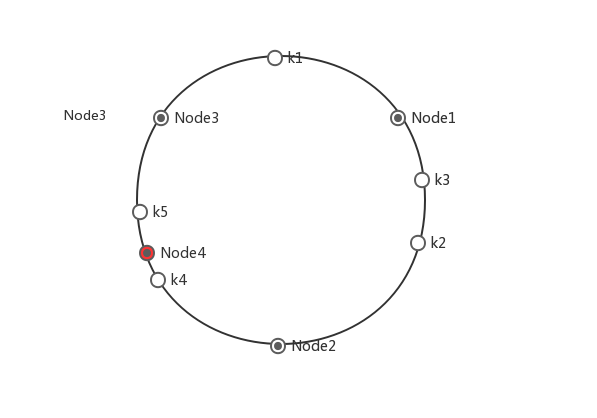
可以看到只有k4需要迁移.
实际中,为了hash之后的均匀性,会将每个node虚拟出多个虚节点.具体参见下边一个具体的go代码实例
go代码实现
我们看一个具体的go代码实现
执行如下命令获取该实现:
1 | go get stathat.com/c/consistent |
通过go doc简单看下大概结构
1 | go doc consistent |
1 | go doc -u consistent.Consistent |
看一个示例:
1 | ch := consistent.New() |
结果如下:
1 | Node3 Node2 Node3 Node1 Node3 Node2 Node3 Node1 Node1 Node1 Node2 Node2 |
0-11增加Node4之后没有迁移,11-20中可以看到增加了Node4.修改一下虚拟节点的个数为1,如下:
1 | ch := consistent.New() |
再次运行,结果如下:
1 | Node3 Node2 Node2 Node2 Node3 Node2 Node2 Node2 Node1 Node2 Node1 Node2 |
虚拟节点个数设置为1之后,可以看到两点改变:
- 0-11的分布不再均匀,8个数在Node2,2个在Node3,2个在Node1
- 增加节点4之后,2,6,11三个数做了remap.可以看到remap了三个key,效果不如默认20个虚拟节点的情况
Consistent结构体分析:
circle key为每个node hash之后的index值,注意默认会增加20个虚拟节点,值为具体的节点名称- members key为节点名称,值为bool类型,表明该节点是否存在
- sortedHashes uint32切片,每个值为circle中的key,并且按递增序排好
- NumberOfReplicas int 虚拟节点个数
- count int64 真实节点个数
- scratch [64]byte
- sync.RWMutex 节点修改时需要加锁
简单看一下增加节点以及获取key的代码:
1 | func (c *Consistent) Add(elt string) { |
关键步骤如下:
- 加锁然后调用Consistent的add方法
- 根据设置的虚拟节点个数,拼接key(c.eltKey方法,例如elt为Node1时会拼接20个key,分别为0Node1,1Node1,2Node1一直到19Node1),对20个key求hash值(c.hashKey方法),然后以hash值为index放置到c.circle中.可以看到c.circle这个map的index为hash之后的一个uint32(最大为2^32-1),值为Node1
- c.members中增加Node1节点
- 更新c.sortedHashes值
- 更新c.count即节点个数
看一下c.sortedHashes的构造:
1 | func (c *Consistent) updateSortedHashes() { |
- 获取c.circle中的index,排序之后赋值给c.csortedHashes
get函数如下:
1 | func (c *Consistent) Get(name string) (string, error) { |
- 加锁,如果c.circle中无值则直接返回错误
- 对name做同样的hash,调用c.search方法获取该hash值在c.sortedHashes中的索引
- c.sortedHashes中保存的是c.circle的索引,c.circle的值即为相应的节点
1 | func (c *Consistent) search(key uint32) (i int) { |
- c.search的关键步骤为sort.Search,该函数会二分查找到一个满足条件的最小index并返回