leveldb是一款google开源的key/value持久化存储.facebook基于其开发了rocksdb.各大厂商如360 pika,阿里巴巴x-engine等基于其开发出了自己的k/v持久化存储.Hbase的底层存储方式也基本类似leveldb.
该系列文章会通过源码深入分析leveldb实现.
API
leveldb是一个storage library,对外提供三个主要接口
1 | Put(key,value) |
Put接口存储一个key/value对,Get接口通过key获取其value值,Delete接口删除一个key/value对.如果对同一个key Put两次,两次的key在内部保存时会通过增加一个sequence字段来区分.如果Delete一个key,也只是将该key的value设置为null,并且标记该key为删除.
key/value在日志中保存格式如图1-1

读写顺序
leveldb写入分两步, 第一步写入一个redo log(保证断电或系统crash时数据的完整性),第二步写入一个memtable,memtable是一个skiplist的组织形式.可以看到写入会相当高效,只是一个log的磁盘顺序写以及一个内存skiplist的插入操作.
读取时首先从内存中读取(包括memtable和immutable memtable),如果没有读取到,则从磁盘上依次从level0,level1直到最后一个level读取(一般来说,会首先通过布隆过滤器判断是否有该值,是一个quick path,能快速过滤不存在的值)
内存中除了memtable可能会存在一个immutable memtable,即一个只读的memtable,这种双buffer的设计是出于什么考虑呢?
首先leveldb不同于redis,redis的数据都是存储在内存之中,而leveldb的数据存储于硬盘.内存操作肯定是快于硬盘,但一则内存贵,二则内存毕竟容量有限.leveldb的memtable是限制容量的,超过容量需要dump到磁盘.那么dump时为了不阻塞写入,首先将memtable赋值给immutable memtable,然后新建一个memtable继续写入.后台有线程会将immutable memtable写入磁盘.
接着考虑第二个问题,为何需要多个level?
首先memtable中的key是有序的,但是会有重合,所以dump到磁盘形成level0的文件的时候每个文件的key是会有重合的.这会给读操作带来性能上的损耗(因为可能需要读取多个文件).因此首先level0的文件个数是有限制的,其次会将level0的文件下沉形成一个无key重叠的level1.如果说level1是为了提高读取效率,为什么需要level2,level3等更高层次的文件呢?这个应该是跟compaction有关,后文详细叙述.
第三个问题,每个level是文件数量增加,单文件大小不变还是文件大小增加,文件数量不变抑或文件大小和数量都增加呢?
leveldb是单文件大小不变,每一层的总大小按10倍增加,也就是总的文件数量会增加.该问题的具体原因及原理留待思考,后文详述
redo log
首先看看leveldb的redo log的写入格式及一些操作
编写如下写入代码:
1 | leveldb::WriteOptions writeOptions; |
写入两次Key0,第一次value值为”Test data value: 0”,第二次value值为”Test data value: 1”
在写入日志记录处打断点:
1 | b $leveldbhome$/db/log_writer.cc:36 |
执行到该步之后,我们输出写入日志的数据:
1 | (gdb)p *ptr@37 |
参考上文key/value保存格式:
“\005\000\000\000\000\000\000\000”:8字节为sequence,在此处为5
“\001\000\000\000”:4字节的count,说明此batch中只有一条数据.batch后文详述
“\001”:1字节的type,表明这是一个key/value对
“\004Key0”:key长度为4,值为Key0
“\022Test data value: 0”:value长度为18,值为”Test data value: 0”
我们接着看一下保存在log中的格式,代码参见db/log_writer.cc 36行开始的如下函数
1 | Status Writer::AddRecord(const Slice& slice) |
log格式如图1-2
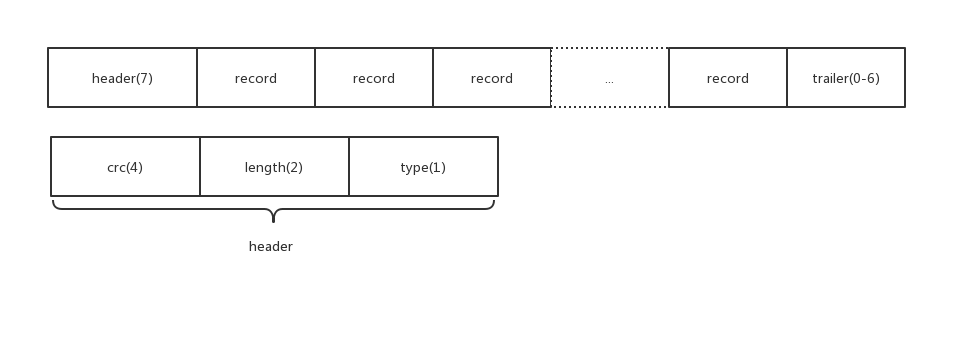
crc和length很好理解,type和trailer是做什么用呢?
首先一个log按32KB大小的block写入,如果一个block在某次写入后剩余字节数小于等于6字节(头部为7字节,即如果写不下一个头部,则附加trailer),则按剩余长度补充\x00,即trailer.
如果一次写入超过32KB,那么该写入需要跨多个block,通过type字段来区分该block是写入的哪个位置.
type类型如下:
1 | kFullType = 1, |
kFullType即一个block可以容纳该次写入,其他三项表明该block分别是此次写入的开始,中间部分和结尾
我们看下实际日志文件的输出:
1 | a@zsh_test ~/leveldb/sample/testdb$ls -rlht |
逐行分析如下:
- 4字节crc,2字节length为2*16+5=37,1字节type为01即kFullType.8字节sequence为1,4字节count为1,共19字节
- 1字节type为01表明是key/value,1字节key_len为4,4字节key为Key0.1字节value_len为18,18字节value为”Test data value: 0”.共25字节
- 接下来是一个新的block,解析同上文.只是sequence变为2
可以看到length字段是每个record的大小
打开一个数据库
1 | Status DB::Open(const Options& options, const std::string& dbname,DB** dbptr) |
该接口位于db_impl.cc文件
对一个db执行put,get,delete操作之前需要先调用Open接口打开一个db.其中第二个参数是db所有文件的父节点,例如:
1 | a@zsh_test ~/leveldb/sample/testdb$ls -rlht |
dbname如果为testdb,则会在testdb目录下生成上述文件
我们看下Open接口做了哪些事情:
- 构建一个DBImpl实例,初始化各种实例变量.详见如下代码:其中比较关键的是versions_这个变量,为一个VersionSet.Version相关的有三个类型,Version,VersionEdit,VersionSet,主要是用来实现MVCC.VersionSet是一个双向环形链表,链表节点为一个个Version,每次当文件有变动时(例如compact)会生成一个VersionEdit记录变动.具体后文详述
1
DBImpl* impl = new DBImpl(options, dbname);
- 执行recover过程.recover主要分为两步,其一为通过MANIFEST文件中记录的VersionEdit,逐步应用之后生成一个当前的Version;其二为通过LOG文件中的数据生成memtable.详见如下代码:Recover中依次执行如下:
1
Status s = impl->Recover(&edit, &save_manifest);
* 创建dbname这个目录,如果首次打开数据库,则创建一个CURRENT文件并且指向MANIFEST-000001. * 执行VersionSet的Recover函数生成当前Version * 执行DBImpl::RecoverLogFile函数通过未dump入磁盘的log文件生成memtable - 生成log写入句柄和一个新的memtable
- 执行VersionSet::LogAndApply生成一个新的MANIFEST文件
生成的MANIFEST文件包括如下内容:MANIFEST保存格式同上文所述的log,我们依次查看.1
2
3
4
5a@zsh_test ~/leveldb/sample/testdb$xxd MANIFEST-000002
0000000: 56f9 b8f8 1c00 0101 1a6c 6576 656c 6462 V........leveldb
0000010: 2e42 7974 6577 6973 6543 6f6d 7061 7261 .BytewiseCompara
0000020: 746f 72a4 9c8b be08 0001 0203 0900 0304 tor.............
0000030: 0400* 4字节crc,2字节length为28,1字节type为full类型.然后是1字节的Version相关字段表示,01表示kComparator,1字节长度为26,接下来是comparator名字:leveldb.BytewiseComparator,正好是26个字节. * 同理接下来首先是4字节crc,2字节length为8,1字节type为full类型.然后是1字节的Version相关字段,02表示kLogNumber,1字节为log_number_为3;1字节的Version相关字段,09表示kPrevLogNumber,1字节为prev_log_number_为0;03为kNextFileNumber,next_file_number_为04;04为kLastSequence,last_sequence_为0 - 删除过期文件,如果需要compact,则执行compact
- 将impl赋值给Open函数签名中的dbptr并返回(DBImpl继承于DB,因此可以赋值)