memtable持久化时机
当我们使用Put命令时,会经过如下调用链:
DBImpl::Put->DB::Put->DBImpl::Write->DBImpl::MakeRoomForWrite
该函数进行了如下判断:
- level0的文件数超过了8个,该次写入阻塞1ms
- 当前memtable中写入量小于4M,则可以继续直接写入
- 如果存在immutable memtable,则阻塞等待immutable memtable,直到其dump入磁盘
- 如果level0的文件数超过了12个,阻塞等待compact level0的文件
上述条件都不满足时,执行如下代码:
1 | delete log_; |
原来的memtable赋值给immutable memtable,然后新建一个memtable,并进入compaction流程
sstable结构
接下来的关键函数调用链为DBImpl::BackgroundCall()->DBImpl::BackgroundCompaction() -> DBImpl::CompactMemTable()
该函数执行memtable dump到磁盘的流程,关键包括如下两点:
- 从memtable生成sstable并持久化到磁盘,函数为WriteLevel0Table
- 由于涉及到新文件的生成,因此需要更新manifest,函数为versions_->LogAndApply(&edit, &mutex_)
manifest的生成见前文,本文重点描述memtable持久化到sstable.涉及sstable的结构及关键代码逻辑
首先看sstable的结构图:
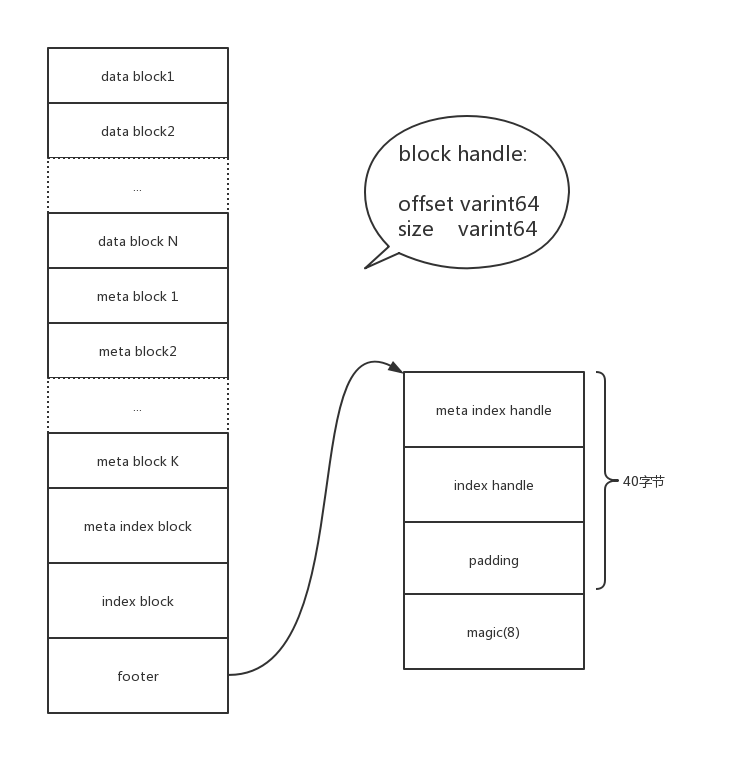
上图关键点说明如下:
- data block中存放有序的key/value对,可压缩
- meta block可存储多种类型,常用的是bloom filter
- metaindex block中对应于每个meta block存放一个entry,key是meta block名称,值是指向对应metablock的一个BlockHandle(参见图,每个BlockHandle存放两个字段,一个是起始偏移量,一个是大小,通过BlockHandle去定位一个block)
- index block中也是对应于每个data block存放一个entry,key是大于等于该data block中最大值,小于下一个data block中的起始值.value也是指向data block的一个BlockHandle
- 最后是footer,固定大小,根据footer能够首先定位metaindex block和index block的位置,然后通过这两者定位data block和meta block的位置
data block中的key/value pair保存格式如下:
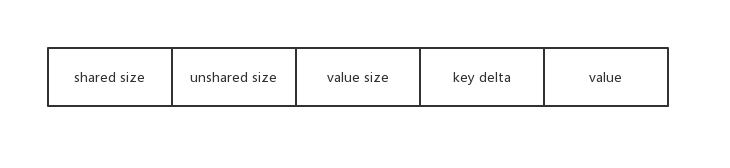
由于key是有序排列的,所以key之前必然会有重复前缀,每次插入时会与之前插入的key做比对,然后依次记录能共享的前缀字符数,不能共享的字符数,value的字符数以及key不能共享的部分和value部分
注意其中会有一个重启点的概念,从每一个重启点开始之后的key/value对才会共享前缀,leveldb中默认16个key/value对有一个重启点
每个block默认的大小为4k,写满4k后会flush依次.flush的时候会将重启点和trailer附加上,所以一个完整的data block的格式如下:
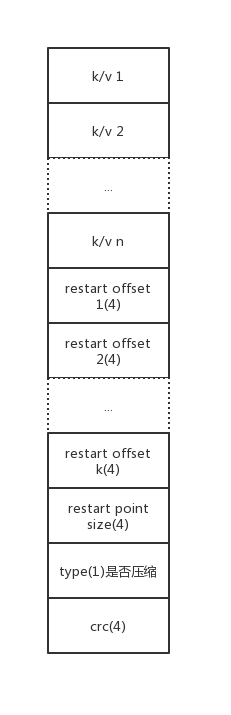
Flush的过程中还有关键的一些步骤,看下代码:
1 | void TableBuilder::Flush() { |
- 标记1处:在pending_handle中增加该block的大小和偏移量, 写index block时需要这些信息
- 标记2处:将pending_index_entry置为true,因此在下次执行TableBuilder::Add时会去写index block.
所以写入index block也比较简单,首先也是一个key/value对,格式同data block,但是key是大于等于上一个data block的最大值,小于下一个block的最小值,value是pending_handle中记录的上一个block的大小和偏移量(大小和偏移量会被encode为一个string)
最终,在TableBuilder::Finish()中将index block写入,footer写入.即结束了一个sstable的构造.
bloom filter写入
第二节其实没有讲解meta block以及metaindex block的写入.这两者在当前情况下为一个bloom filter.我们看下如何生成这个meta block
默认情况下,options中的filter_policy为null,可以赋值为NewBloomFilterPolicy(),来启用bloom filter.
基本原理为构造bloom filter时需要传入一个唯一的参数bits_per_key_,代表每一个key需要多少bits,bloom filter为了达到尽量低的false positive,可以计算出一个hash次数的最优解,为
1 | k=(m/n)*ln2 |
其中m为占用的bits个数,n为key的个数,m/n即为bits_per_key_参数的值,因此bits_per_key*ln2即为每个key需要的hash次数.leveldb中每2K的数据生成一个bloom filter.具体调用链为:
FilterBlockBuilder中的AddKey->StartBlock->Finish,分别对应于data block中key/value的添加,一个block写满后的flush以及最后构造一个sstable结束的时候.
生成的bloom filter放置于meta block,格式如下:
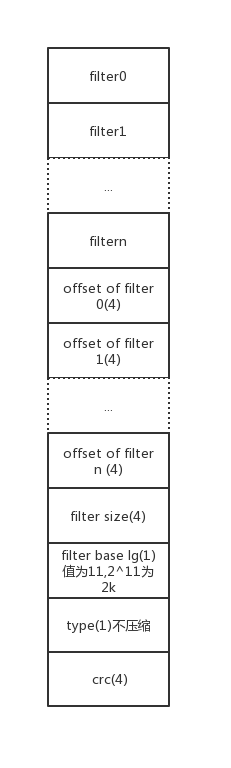
其中每个filter的格式为
1 | k|每个key占用的bits*key的个数. |
k为哈希次数
metaindex block的存储格式为:
1 | key: |
至此,sstable的写入已经介绍完毕.