CRDT
CAP理论证明三者之间不可能同时完全满足,如果分布式数据库必须满足P-分区容忍性,CA只能占其一.A是可用性,C是一致性.
CRDT(Conflict-Free Replicated Data Type)能根据一定的规则自动合并,解决冲突,达到最终一致的状态.即可以满足AP,但会保证最终是一致的.
参考链接1有详细的CRDT介绍,链接2是Redis lab基于CRDT实现的分布式数据库系统,链接3介绍Roshi,也是一个基于CRDT的开源分布式数据库,本文重点关注Roshi
Roshi起源
SoundCloud公司(类似于喜马拉雅),会有大V和粉丝人群,如果一个大V发布一条音频,那么有如下两种方式发布给粉丝:
- Fan out on write:每个粉丝有一个收件箱,将该信息放入所有粉丝的收件箱.很明显,这样有利于粉丝的读取,但是会有大量的写和冗余数据.
- Fan in on read:将信息放入大V的发件箱,当粉丝查看的时候从所有该用户关注的大V信箱拉取信息并且合并展示.这种方法不利于读取,如果有大量的关注,那么得从大量的发件箱去拉取数据.但是由于数据冗余很小,可以考虑将数据放入内存,例如Redis.那么Redis如何实现为一个分布式数据库就提上了日程
Roshi实现
Roshi,一个分布式时间序列的数据库.底层使用Redis ZSET存储数据(模拟每个人的发件箱).整体架构如下:
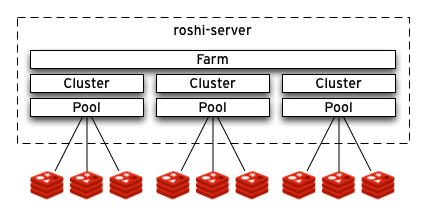
- Pool:基于key的sharding
- cluster:实现Insert/Select/Delete API
- farm:Writes发往所有的clusters,可以配置quorum,大于等于该quorum返回成功.Read有不同的策略,生产上使用的读策略最好允许read-repair(下文介绍)
- roshi-server:给farm提供rest http 接口.无状态并且兼容12-factor
- roshi-walker:扫键以便触发read repairs
API
- Insert(key, timestamp, value)
- Delete(key, timestamp, value)
- Select(key, offset, limit) []TimestampValue
select的offset,limit用于分页获取
数据结构
CRDT需要满足交换律、结合律以及幂等性,Roshi实现的是LWW-element-set,即 Last Writer Wins element set.满足以下两个条件:
- 如果一个元素最近一次操作是add,那么它肯定在集合中
- 如果一个元素最近一次操作是remove,那么它肯定不在集合中
具体实现原理为:集合痛殴两个集合A和R表示,A为add set,R为remove set,增加元素时增加一个tuple例如(e,timestamp)到A中,删除一个元素时增加一个tuple例如(e,timestamp2)到R中.那么检查一个元素e是否在集合S中,即需要查看e是否在A中,并且在R中没有大于A中时间戳的e存在
Roshi中操作如下,三列分别代表原始状态,操作,最终状态
| Original state | Operation | Resulting state |
|---|---|---|
| A(a,1) R() | add(a,0) | A(a,1) R() |
| A(a,1) R() | add(a,1) | A(a,1) R() |
| A(a,1) R() | add(a,2) | A(a,2) R() |
| A(a,1) R() | remove(a,0) | A(a,1) R() |
| A(a,1) R() | remove(a,1) | A(a,1) R() |
| A(a,1) R() | remove(a,2) | A() R(a,2) |
| A() R(a,1) | add(a,0) | A() R(a,1) |
| A() R(a,1) | add(a,1) | A() R(a,1) |
| A() R(a,1) | add(a,2) | A(a,2) R() |
| A() R(a,1) | remove(a,0) | A() R(a,1) |
| A() R(a,1) | remove(a,1) | A() R(a,1) |
| A() R(a,1) | remove(a,2) | A() R(a,2) |
其他实现
Redis lab的商业版实现包括了更多的类型,包括register(string),counter等等.并且实现CRDT的方式也略有不同.详情可参考后文链接.