内存管理涉及到的算法,主要包括队列、各种位运算。文中使用Go版本为1.17.6
位运算
使用位移操作,实现各类算法
2的幂次
判断一个正整型数字,是否是2的幂次方,例如 1=>false,2=>true
1 | func IsPowerOf2 (n uint) bool { |
2幂次方的数字只有最高位为1,其余位都为0,例如2=>10,4=>100,8=>1000。所以n&(n-1)等于0
对齐
内存管理中会要求某个地址按2的幂次方对齐,常见的例如按8字节对齐,假设地址为100,则按8字节对齐后为 8 * 13 = 104 ,地址为 112,则对齐之后也为112。
对齐就是将地址调整为 8 的整数倍
向上对齐
1 | func alignUp(n, a uintptr) uintptr { |
向下对齐
1 | func alignDown(n, a uintptr) uintptr { |
向上,则n + a -1 ,向下,直接使用n,同理,计算ceil(n/a),将n/a后向上取整
1 | func divRoundUp(n, a uintptr) uintptr { |
正整数二进制表示后末尾连续0个数
例如4=>100,则末尾连续0的个数为2,5=>101,末尾连续0的个数为0。我们看下移位版64位正整型末尾0的个数
1 | func trailingZeros(n uint64) int{ |
Go使用http://supertech.csail.mit.edu/papers/debruijn.pdf 中的算法,代码为:
1 | func Ctz64(x uint64) int { |
详细解释参考论文
Go中8位整型直接使用查表法获取,代码如下:
1 | func Ctz8(x uint8) int { |
8位只有256个元素,直接查表获取,例如0=>0x08,1=>0x00,2=>0x01
无锁队列
Go内存管理mcenter结构体保存了两个span队列,一个是有空闲元素的,一个没有。span队列使用无锁队列实现,其结构体如下:
1 | type spanSet struct { |
一个mspan至少代表一个page,大小为8KB,则一个数组占用 512 * 8 KB = 2^9 * 2^13 B = 2^22 B = 4MB。spine初始容量为256,则一个spine可容纳 256 * 4MB = 2^8 * 2^22 B = 1GB。示意图如下: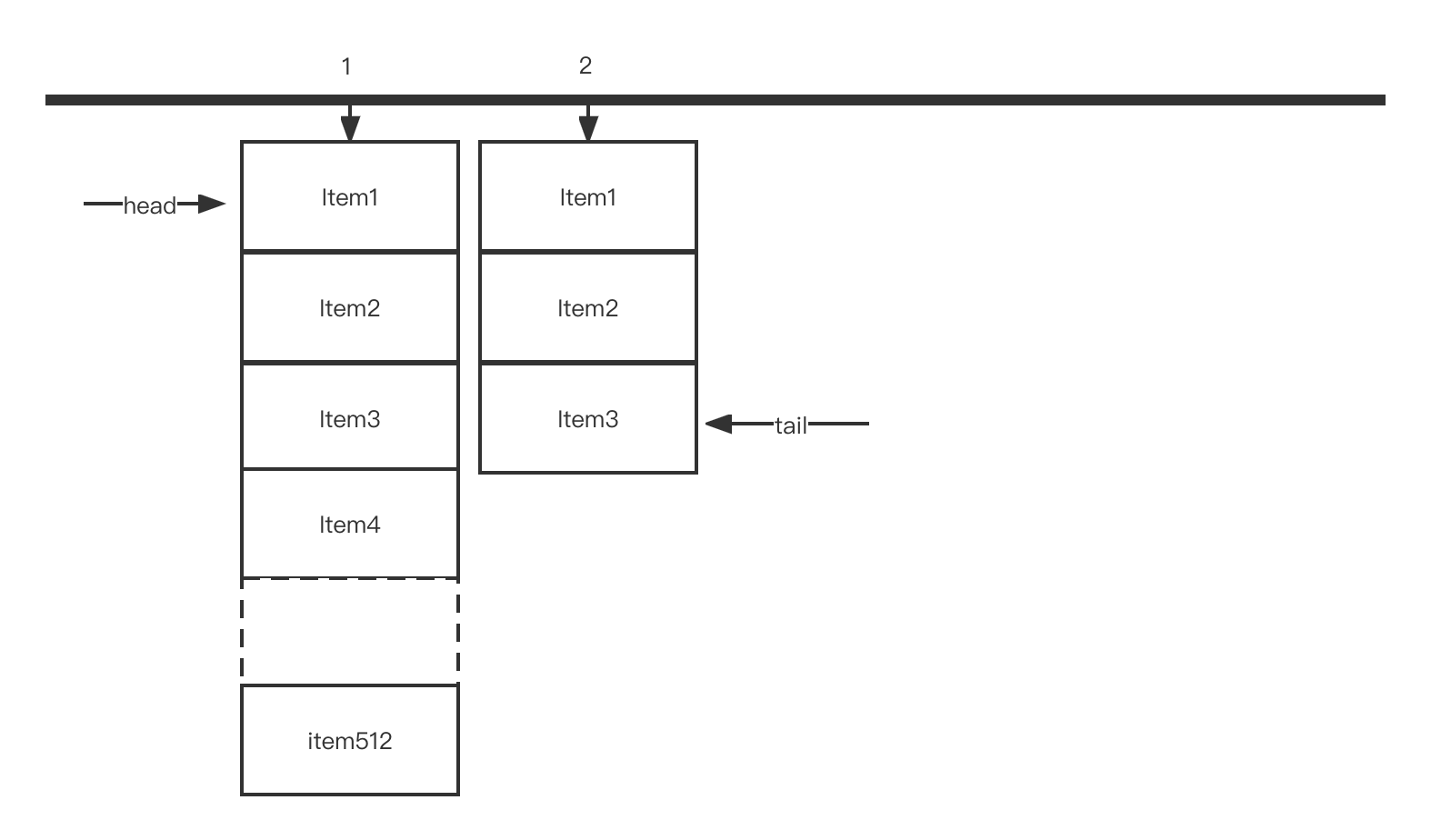
spine类似一个切片,大小不够时,会进行2倍的扩容,每次写入数据时通过尾部压入,弹出时通过头部弹出,除了扩充spine容量之外,其他时候不需要加锁,通过原子操作进行。代码如下:
1 | func (b *spanSet) push(s *mspan) { |
1 | func (b *spanSet) pop() *mspan { |
总结
Go语言代码需要极致考虑性能,因此其可读性并不高。并且语言功能和实现方法还在不断的更新变动之中,希望文章能给大家了解Go实现有所帮助。